When you first start tackling a DITA conversion, it’s difficult to get a handle on just what comprises a single file. Is it one topic? Is it multiple topics? How long should a file be? How short can it be? We’ll tackle these questions in this article.
Perfect File
The perfect DITA file is one that contains one topic, where that topic is as long or as short as it needs to be.
The length of a topic depends entirely on the subject matter and issues of usability. Generally, the litmus test is asking yourself “Can a user navigate to this one topic and have all the information they need for it to be usable and stand on its own?” If it’s too short, you’re forcing them to navigate away to find more information. If it’s too long, it becomes too onerous to follow.
Your file should contain just one topic, be it task, concept, or reference, regardless of the length of your topic.
Shortest File
The shortest file allowed in DITA is a topic that contains only a title element and nothing more.

This is absolutely allowed but it is something that you would only do for a specific reason, such as adding another level of headings.
Longest File
The longest file you should have is one that supports your requirements. For most technical publications content, you should only have one topic per file.
Note: An exception to this rule is if you’re authoring training content using the DITA Learning and Training Specialization; there are very good reasons for having many topics in a single file in that case, but those would all be learning and training topics, not the core concept, task, and reference that DITA is built upon. Note that this is true as of DITA 1.2 but may change in the not-so-distant future.
Chunking
DITA architecture allows you to nest many topics into one file. However, doing so introduces major limitations on reuse. If you nest topics into one file, you will be sacrificing the flexibility that DITA introduces. It’s like choosing to hop on one leg instead of running on both.
Breaking each topic out into its own file is what we call “chunking.” One purpose of chunking is to allow the authors to have incredible flexibility when it comes to reusing this content.
Consider this nested task within a task, where two tasks are in the same file.

If I want to include the information about studying with a master somewhere else, such as a guide for becoming a senator, I’ll be out of luck because I haven’t separated my two tasks into separate topics—when they’re in the same file, where one goes, the other must also follow.
Once a topic is in its own file, an author can pull that topic into any deliverable that needs it. It’s not uncommon for one file to be part of up to ten or more deliverables. If you have multiple topics in that one file, then they all must be reused along with the one you want, without the possibility of even changing the order of them.
There are many other good reasons to chunk. For example, if your content needs to be reorganized, you can quickly drag and drop topics that are each in their own files. All navigation and linking is automatically updated based on your new organization.
How It All Comes Together
Chunking content into individual topics is the first major hurdle that authors face when adopting DITA because it’s so far away from our training and understanding of writing in chapters, books, and documents. It’s not clear how all those tiny little topics come together. And be warned, you will have hundreds of topics that make up just one deliverable.
Enter the DITA map, the great glue that holds it all together.
You can think of a DITA map (which has a .ditamap file extension) as nothing but an organizational mechanism or even as a Table of Contents. A DITA map itself has very little content. It usually contains just a title. What it does have, though, are topicrefs, which are references to all those files you’ve authored.
Here’s a visual representation of a map, where I’ve told it to “pull in” my two topics (with a hierarchy, one nested below the other). When I create my map, I add the topics that are relevant to this deliverable. The map simply references them using a file path with the href attribute.
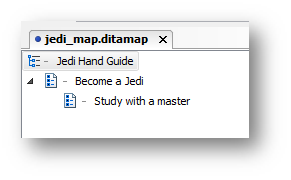
That same map in code view looks like this:
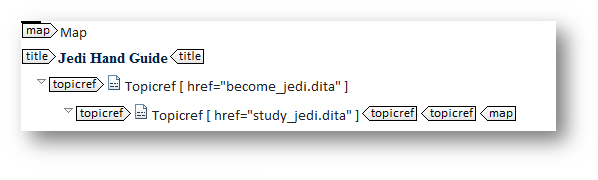
The only thing that’s actually typed into this map is the content in the element. The other two objects, the topicrefs, are pointing to the files that are my two tasks using the href value, in this case simply the names of the files: become_jedi.dita and study_jedi.dita.
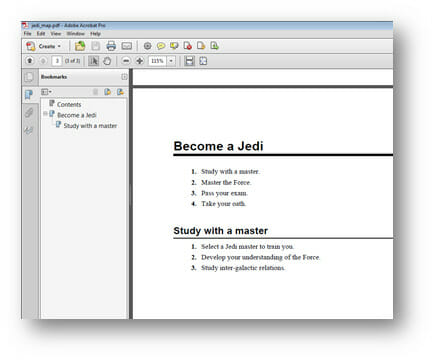
When you publish a DITA map with all your topics referenced, you get a single deliverable with all your content. For PDFs, you’ll have content that looks exactly like your PDFs created from FrameMaker, Word, InDesign or whatever else you have used. For HTML output, each file becomes its own page, with automated navigation to all the other pages. All outputs are entirely customizable.
Summary
Although the length of your topics will vary depending on the subject matter, your files should contain just one topic. Use your DITA map to bring your topics together, giving you the flexibility that DITA promises, including topic-level reuse and the ability to quickly reorganize your content.