
WEBINAR | How To Get A Customized DITA XML Conversion Pipeline Built Easily, Quickly, and Possibly For Free
For beginners in DITA XML or for those dealing with ongoing content migration, we provide an easy solution to get up-and-running with your own customized conversion pipeline ...

WEBINAR | Live Demonstration: Comprehensive Conversion of Pharmaceutical Content into DITA XML
Stilo showcases a comprehensive, end-to-end process for converting pharmaceutical documentation, beginning with the source DOCX Word file ...

WEBINAR | Maximizing Efficiency: The Benefits of Automated Content Conversion
One of the main benefits of using a structured format such as DITA is the ability to reuse content, but realizing where reuse is beneficial and estimating the probable savings ...

WEBINAR | Assessing the Amount of Redundant Content in Our Documentation
Join TJ as he uses Stilo’s Analyzer 2.0 to investigate source content for hidden reuse in this webinar.
WEBINAR | Recognizing Potential Reuse in Your Content Before Conversion
One of the main benefits of using a structured format such as DITA is the ability to reuse content, but realizing where reuse is beneficial and estimating the probable savings ...

WEBINAR | Semantic markup. Why do I need it, and how do I do it?
In the past, we have produced documents with a focus on how they look when published. Page layout, font face, font size, bolding and italics have been useful ...

WEBINAR | How An Automated DITA Conversion Can Help Your Authoring Team
Join Jacob Brennan in this session as he uses Stilo’s Migrate to convert legacy content to structured DITA.

WEBINAR | What an automated DITA conversion can do for you (and what it can’t)
Join Helen St. Denis in this session as she uses Stilo’s Migrate to convert legacy content to structured DITA.
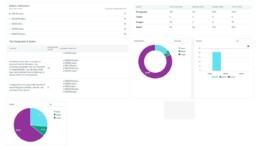
WEBINAR | How much redundant content do I really have? Actualizing the reuse in our documentation.
Join TJ Dhaliwal in this session as he uses Stilo’s Analyzer and Migrate to investigate source content for similar and exact matches.
WEBINAR | Analyzer 1.0 – Identifying Content Reuse
In this webinar we will demonstrate how to analyze Word content, calculate & navigate reuse potential, and generate beautiful reports estimating cost savings.